编译一时爽,环境火葬场
因为使用A*算法对于路径的寻找需要更高的效率,很明显,python自身完全不能满足我们的需求,因此使用C++编写python扩展变得非常重要.
不幸的是,我昨天花了整整一天都没有解决这个问题,但是今天却进行的异常顺利,下面我来讲一下在使用C++编写python中的几个坑
编译一时爽,环境火葬场
因为使用A*算法对于路径的寻找需要更高的效率,很明显,python自身完全不能满足我们的需求,因此使用C++编写python扩展变得非常重要.
不幸的是,我昨天花了整整一天都没有解决这个问题,但是今天却进行的异常顺利,下面我来讲一下在使用C++编写python中的几个坑
对于一个被控制对象$\mathcal{P}$,我们需要搭建一个反馈控制系统,如图所示: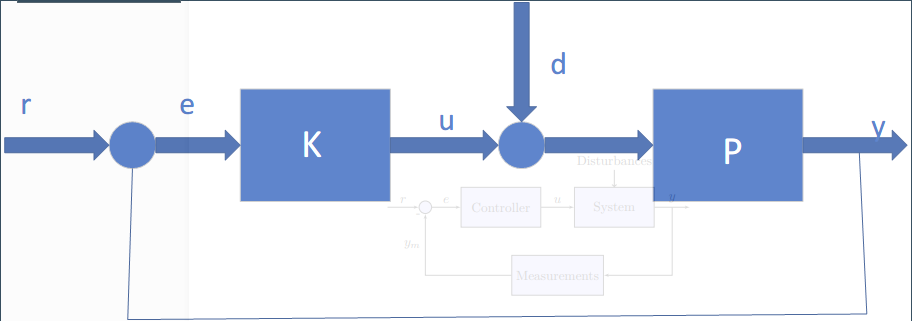
其中$\mathcal{K}$为控制器,$r$为目标值,$u$为控制输入,$d$为扰动,$y$为输出,$e$为误差,下面来分别介绍稳定性,时域特性以及频域响应特性
经过数日的鏖战,我算是把一个路径规划程序给写完了,然而,这其中隐藏着不少的问题,以至于虽然这个程序理论上能够给出正确答案,但是实际上由于某些原因完全无法使用,下面我将这个记录下来,以供参考
由于之前写了一个误差计算脚本,采用了万能的nohup python calc_error.py >logs &实现了后台运行,但是在实际使用过程中,经常会遇到异常或者一些奇奇怪怪的问题,自己每次上线检查也麻烦,遂思考能不能用邮件来解决问题.
我参考这篇文章,学习一下使用python发送邮件
我们分为两部,一方面是写邮件的过程,需要特定的邮件头和附件,这一部分使用的是email模块进行
我在使用
pip install email的时候一直出错,但是到pip install emails就可以,目前不确定两者关系,但是都可以使用import email调用
而编写完邮件后,对于邮件的发送则是通过smtp服务进行,这一部分则是用smtplib实现,而其安装可以用pip install aiosmtplib进行
smtp我计划使用Gmail对这些邮件进行配置,为此,我打开了Gmail中的imap和pop3服务,关于Gmail更多信息如下,摘自于此
| 内容 | 配置 |
|---|---|
| 接收邮件 (IMAP) 服务器 | imap.gmail.com 要求 SSL:是 端口:993 |
| 发送邮件 (SMTP) 服务器 | smtp.gmail.com 要求 SSL:是 要求 TLS:是(如适用) 使用身份验证:是 SSL 端口:465 TLS/STARTTLS 端口:587 |
| 完整名称或显示名称 | 您的姓名 |
| 帐号名、用户名或电子邮件地址 | 您的完整电子邮件地址 |
| 密码 | 您的 Gmail 密码 |
下面代码展示发送测试邮件过程
1 | import smtplib |
这个代码确实可以发送邮件,测试完成
我们可以利用MIMENonMultipart中的MIMEText类来发送我们得到的csv文件
可以参考这篇文章
自然,我们可以实现更多内容(比如HTML等),但是我目前不需要,就先留在这里,可能未来还会更新
在编写程序,尤其是某些运行时间长,中间存在可能错误的程序,往往需要记录日志以便于调试.
但是日志的编写往往存在大量重复劳动,并且对于我目前的状况来讲可能需要在已有的程序中添加日志代码.
经过相关资料查阅,我找到了一个内置logging库,其可以较好地实现对于日志的编写.但是查阅了一下相关资料后,发现似乎logging的使用较为复杂,我们往往不需要那么复杂的应用场景,因此我在这里选择另外一个库loguru对日志进行记录
如果使用anaconda,可以用以下命令安装:
1 | conda install -c conda-forge loguru |
我们可以直接利用封装好的logger对象,直接对不同级别的日志进行输出,例如使用以下代码可以实现不同级别的日志:
1 | from loguru import logger |
可以注意到在运行时,其对于不同级别的结果,有着不同的格式化与颜色

接下来,我们可以注意到logger编写日志的一个优势在于其无需设定复杂的如处理器,过滤器等信息
我们往往需要将数据输出到文件,尤其是在使用如xspec这样自己会有大量数据输出的程序(默认是在sys.std_err中输出),可以使用add改变输出位置(add的具体用法之后会讲)
1 | logger.add("file_{time}.log") |
其中{time}会自动替换为当前时间,还有其他的格式化字典如下:
| Key | Description | Attributes |
|---|---|---|
| elapsed | The time elapsed since the start of the program | See datetime.timedelta |
| exception | The formatted exception if any, None otherwise |
type, value, traceback |
| extra | The dict of attributes bound by the user (see bind()) |
None |
| file | The file where the logging call was made | name (default), path |
| function | The function from which the logging call was made | None |
| level | The severity used to log the message | name (default), no, icon |
| line | The line number in the source code | None |
| message | The logged message (not yet formatted) | None |
| module | The module where the logging call was made | None |
| name | The __name__ where the logging call was made |
None |
| process | The process in which the logging call was made | name, id (default) |
| thread | The thread in which the logging call was made | name, id (default) |
| time | The aware local time when the logging call was made |
输出到文件还有滚动和压缩等功能,在这里不再过多赘述(目前也用不到)
关于字符着色:
字符着色的问题是通过调节
add中的参数colorize来控制的,其添加后有好处有坏处好处在于可以使用
tail -f等很方便看到数据内容坏处在于由于字符串着色的机理是通过添加字符串进行的,会对编辑器查看带来不便
因此可以尝试同时记录两个log
下面是关于更加复杂的过滤器写法和格式化写法的问题,这里不涉及(可能以后会),可以先看参考资料
由于我在学习控制系统的时候,感觉Visio绘图手感像坨屎(我承认是我手不行),但是像流程图这样的东西有特点,即如果你能在这些空间里面把你想要塞的东西全部塞进去,那么优化这样的工作可以是完全交由计算机自行处理的.
在这里,我主要将介绍两种方式进行该类绘图,一种是使用LaTex中tikz包进行绘图,还有一种是使用Graphviz进行绘图
在前面一部分,我们构造了几种分类算法,而在这一部分,我们将介绍利用scikit-learn提供的便于使用的接口进行机器学习
将分成以下几个部分进行介绍:
logistic回归算法,支持向量机,决策树scikit-learn进行一些常见的应用俗话说:天下没有免费的午餐,不同的分类算法具有相应的优势与劣势,在选择的时候需要充分考虑数据的特征以及目的,一般来说,训练一个机器学习模型可以分为以下五步
之前研究过对于MPS010602中的数字信号,应当如何处理(在其中使用二进制位来表示逻辑),今天恰好看到了numpy.bitwise_xor函数,会非常有用,在此记录一下
在numpy库中有相应的逻辑操作函数,而最大的特点就在于它们可以实现向量化,这对于我们应用的场景来说非常重要.
其使用的方法与&类似,主要看代码,以下代码展示如何从一个八进制数取出某一位的数字信号
1 | import numpy as np |
这种标记输入输出均可
另外,机器学习是一回事,这本书中的python代码非常优美,值得学习
在这一部分,我们构造一个简单的线性分类算法实现我们的分类任务
最早的机器学习模型是通过模拟神经元实现的
我们可以定义一个决定函数$\phi(x)$来从输入得到输出
通过将权重矢量与输入矢量点乘后通过一个阈值函数得到输出.
因此,通过计算$sign(\omega^Tx+\omega_0)$即可得到一个二分类输出