标记与术语
特征(features):例如数据的种类(一般以列存储)
样本(samples):一般以行存储,数据列表
这种标记输入输出均可
另外,机器学习是一回事,这本书中的python代码非常优美,值得学习
为分类问题训练简单的机器学习算法 在这一部分,我们构造一个简单的线性分类算法实现我们的分类任务
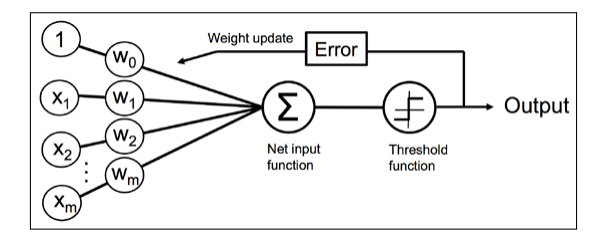
早期的机器学习模型 最早的机器学习模型是通过模拟神经元实现的二分类输出
学习的逻辑 每一次学习,都需要让计算结果更加接近,因此需要更新权重矢量得到$\Delta \omega$学习率
实现 下面我们尝试构造一个类来解决这个问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import numpy as npclass Perception : def __init__ (self,eta=0.01 ,n_iter=100 ,random_state=1 ) -> None : self.eta=eta self.n_iter=n_iter self.random_state=random_state def fitdata (self,X,y ): self.errors_=[] rs=np.random.RandomState(self.random_state) self.w_=rs.normal(scale=0.1 ,size=1 +X.shape[1 ]) for i in range (self.n_iter): error=0 for x,yreal in zip (X,y): ytest=np.where(np.dot(x,self.w_[:-1 ])+self.w_[-1 ]>0 ,1 ,-1 ) self.w_[:-1 ]+=self.eta*(yreal-ytest)*x self.w_[-1 ]+=self.eta*(yreal-ytest) error+=np.count_nonzero(yreal-ytest) self.errors_.append(error) if (error==0 ): print ("The fitting have completed" ) return print ("The max iteration have reached" ) return def net_input (self,X ): return np.dot(X,self.w_[:-1 ])+self.w_[-1 ] def predict (self,X ): return np.where(self.net_input(X)>=0.0 ,1 ,-1 )
在这个类中我们定义fit实现拟合,拟合之后会有两个属性,分别为w_和errors_一个记录了线性参数,另外一个记录了误差
使用鸢尾花数据集训练这个分类模型 为了测试我们这个的效果,我们将对山鸢尾和变色秋海棠两种不同的花进行分类,虽然特征不一定要是二维的,但是为了展示方便,我们使用两个特征萼片长度和花瓣长度作为特征.
我们首先使用pandas将数据从数据库中加载出来,并且看看大概
1 2 3 4 5 import pandas as pddf=pd.read_csv('https://archive.ics.uci.edu/ml/' 'machine-learning-databases/iris/iris.data' , header=None ) df.tail()
0
1
2
3
4
145
6.7
3.0
5.2
2.3
Iris-virginica
146
6.3
2.5
5.0
1.9
Iris-virginica
147
6.5
3.0
5.2
2.0
Iris-virginica
148
6.2
3.4
5.4
2.3
Iris-virginica
149
5.9
3.0
5.1
1.8
Iris-virginica
接下来,我们将前50个山鸢尾和前50个变色秋海棠的记录提取出来,分别标记为-1和1
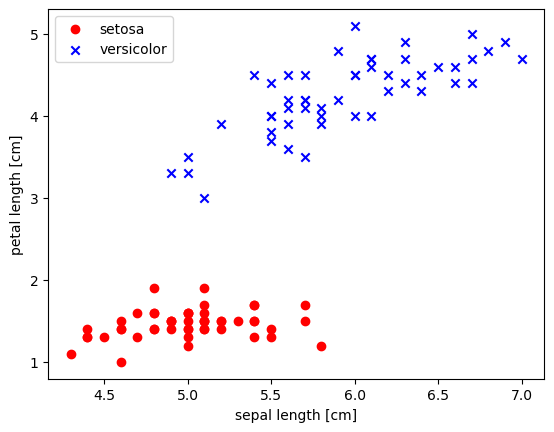
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import matplotlib.pyplot as pltimport numpy as npy=df.iloc[0 :100 ,4 ].values y=np.where(y=='Iris-setosa' ,-1 ,1 ) X=df.iloc[0 :100 ,[0 ,2 ]].values plt.scatter(X[y==-1 ,0 ],X[y==-1 ,1 ],color='red' ,marker='o' ,label='setosa' ) plt.scatter(X[y==1 ,0 ],X[y==1 ,1 ],color='blue' ,marker='x' ,label='versicolor' ) plt.xlabel("sepal length [cm]" ) plt.ylabel("petal length [cm]" ) plt.legend(loc='best' ) plt.show()
我们可以从上面那张图中看出来两种花可以被很好的区分开来,接下来我们来训练一下试试
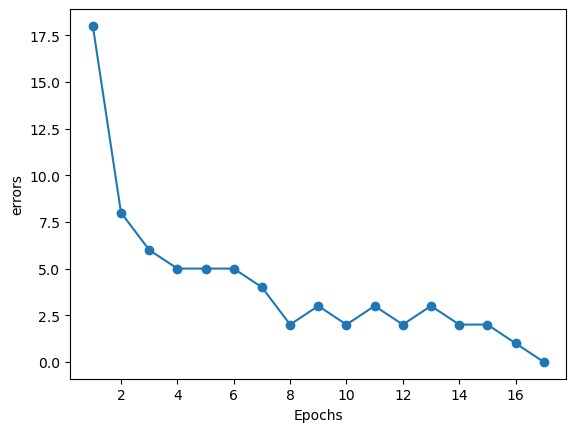
1 2 3 4 5 6 model=Perception(0.001 ) model.fitdata(X,y) plt.plot(range (1 ,len (model.errors_)+1 ),model.errors_,'o-' ) plt.xlabel('Epochs' ) plt.ylabel('errors' ) plt.show()
The fitting have completed
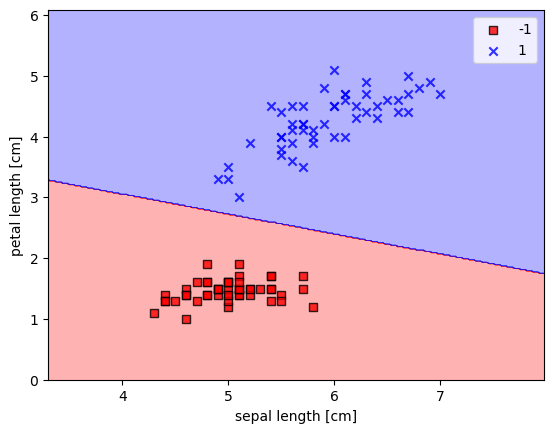
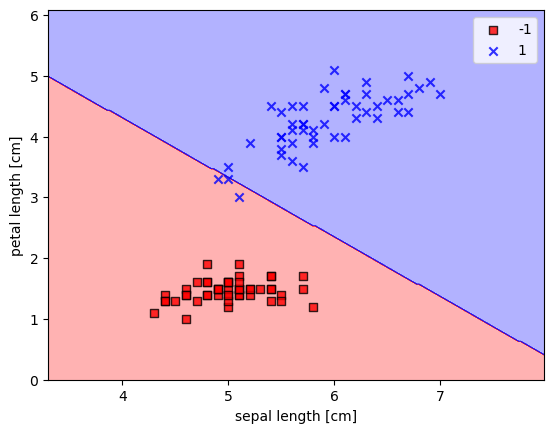
可以注意到,最后的errors已经为0,为了进一步观察我们拟合的效果,我们将定义一个函数用来描绘决定区间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from matplotlib.colors import ListedColormapdef plot_decision_regions (X,y,classifier,resolution=0.02 ): markers = ('s' , 'x' , 'o' , '^' , 'v' ) colors = ('red' , 'blue' , 'lightgreen' , 'gray' , 'cyan' ) cmap = ListedColormap(colors[:len (np.unique(y))]) x1_min,x1_max=X[:,0 ].min ()-1 ,X[:,0 ].max ()+1 x2_min,x2_max=X[:,1 ].min ()-1 ,X[:,1 ].max ()+1 xx1,xx2=np.meshgrid(np.arange(x1_min,x1_max,resolution), np.arange(x2_min,x2_max,resolution)) Z=classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T) Z=Z.reshape(xx1.shape) plt.contourf(xx1,xx2,Z,alpha=0.3 ,cmap=cmap) plt.xlim(xx1.min (),xx1.max ()) plt.ylim(xx2.min (),xx2.max ()) for idx,cl in enumerate (np.unique(y)): plt.scatter(x=X[y==cl,0 ], y=X[y==cl,1 ], alpha=0.8 , c=colors[idx], marker=markers[idx], label=cl, edgecolors='black' )
接下来,我们来展示一下绘图的结果
1 2 3 4 5 plot_decision_regions(X,y,classifier=model) plt.xlabel('sepal length [cm]' ) plt.ylabel('petal length [cm]' ) plt.legend(loc='best' ) plt.show()
C:\Users\lison\AppData\Local\Temp\ipykernel_25612\3891387916.py:20: UserWarning: You passed a edgecolor/edgecolors ('black') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
plt.scatter(x=X[y==cl,0],
刚刚我们实现的可以被认为是一个单层的神经网络
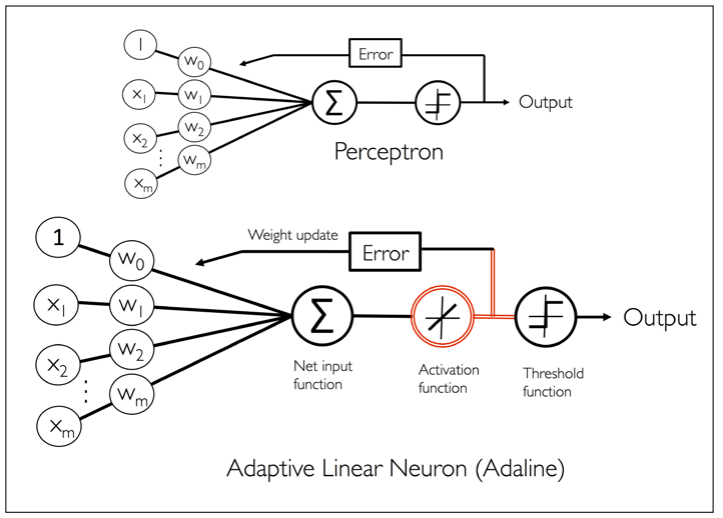
可适应性线性神经元与学习收敛 在这一部分,我们将研究另外一种单层神经网络:ADAptive LInear NEuron(Adaline)Adaline算法与感知机最关键的区别在于权重函数是使用一个线性激发函数而非一个单位阶跃函数,在Adaline算法中ADaline的特殊性可以用下面一张图来展示
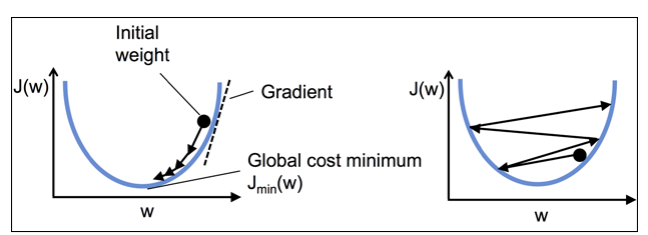
使用梯度下降法最小化损失函数 对于Adaline而言,我们可以定义损失函数$J$并且使用方均根法得到权重梯度下降法 来使损失函数最小,原理为
需要注意一个计算上的不同,在此处我们的计算是所有样本一起算的 而不是像之前一样一个样本更新一次
实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class AdalineGD : def __init__ (self,eta=0.001 ,n_iter=100 ,random_state=1 ) -> None : self.eta=eta self.n_iter=n_iter self.random_state=random_state def fit (self,X,y ): rgen=np.random.RandomState(self.random_state) self.w_=rgen.normal(0.0 ,0.1 ,size=1 +X.shape[1 ]) self.cost_=[] for i in range (self.n_iter): err,errg,errw0=self._calc_cost(X,y) self.cost_.append(err) self.w_[1 :]+=-self.eta*errg self.w_[0 ]+=-self.eta*errw0 def _calc_cost (self,X,y ): yp=(np.dot(X,self.w_[1 :].reshape(-1 ,1 ))+self.w_[0 ]).reshape(1 ,-1 ) err=np.sum ((yp[0 ]-y)**2 )/2 errg=np.dot((yp[0 ]-y),X) errw0=np.sum (yp[0 ]-y) return err,errg[0 ],errw0 def predict (self,X ): return np.where(np.dot(X,self.w_[1 :])+self.w_[0 ]>0 ,1 ,-1 )
接下来,我们将之前的数据输入进去试一试看看如何
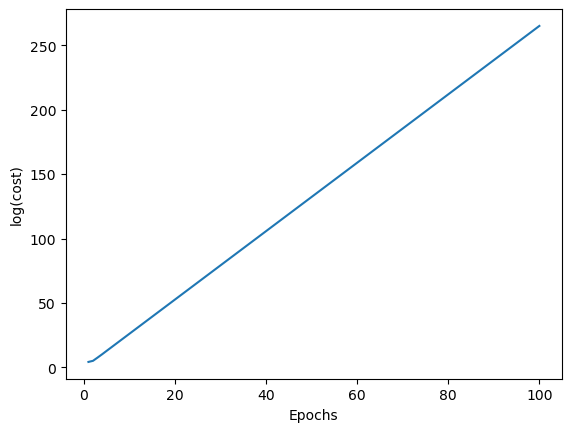
1 2 3 4 5 6 7 8 9 10 11 y=df.iloc[0 :100 ,4 ].values y=np.where(y=='Iris-setosa' ,-1 ,1 ) X=df.iloc[0 :100 ,[0 ,2 ]].values adamodel=AdalineGD() adamodel.fit(X,y) plt.plot(range (1 ,len (adamodel.cost_)+1 ),np.log(adamodel.cost_),'-' ) plt.xlabel('Epochs' ) plt.ylabel('log(cost)' ) plt.show() adamodel.w_
array([-3.89410517e+55, -2.18332011e+56, -2.18332011e+56])
可以发现,程序直接爆炸,此时可能是$eta$调大了,我们把$eta$调为1E-5试试
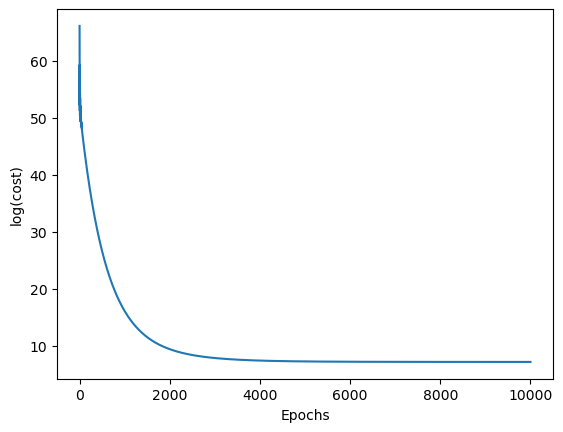
1 2 3 4 5 6 7 8 9 10 11 y=df.iloc[0 :100 ,4 ].values y=np.where(y=='Iris-setosa' ,-1 ,1 ) X=df.iloc[0 :100 ,[0 ,2 ]].values adamodel=AdalineGD(eta=4E-4 ,n_iter=10000 ) adamodel.fit(X,y) plt.plot(range (1 ,len (adamodel.cost_)+1 ),adamodel.cost_,'-' ) plt.xlabel('Epochs' ) plt.ylabel('log(cost)' ) plt.show() adamodel.w_
array([-3.33272936, 0.39707341, 0.40543187])
可以注意到,逐渐在趋向一个稳定值,这之中存在的问题可以用下图展示
1 2 3 4 5 plot_decision_regions(X,y,classifier=adamodel) plt.xlabel('sepal length [cm]' ) plt.ylabel('petal length [cm]' ) plt.legend(loc='best' ) plt.show()
C:\Users\lison\AppData\Local\Temp\ipykernel_25612\3891387916.py:20: UserWarning: You passed a edgecolor/edgecolors ('black') for an unfilled marker ('x'). Matplotlib is ignoring the edgecolor in favor of the facecolor. This behavior may change in the future.
plt.scatter(x=X[y==cl,0],
可以注意到,这种计算方法非常依赖初值,而且最后也没有完全分开来,并不是非常理想,因此需要优化
使用标准化提升梯度下降法效果 标准化是一个机器学习过程中的非常重要的手段,在这一部分中,我们使用一种正态分布标准化
1 2 3 X_std=np.copy(X) X_std[:,0 ]=(X[:,0 ]-X[:,0 ].mean())/X[:,0 ].std() X_std[:,1 ]=(X[:,1 ]-X[:,1 ].mean())/X[:,1 ].std()
在标准化之后,我们将数据输入到前面的模型中
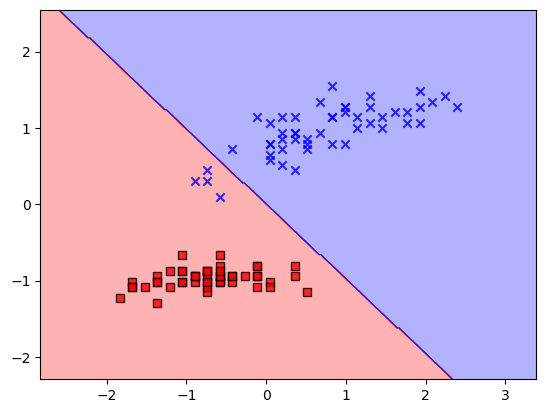
1 2 3 stdada=AdalineGD(1E-3 ,150 ,1 ) stdada.fit(X_std,y) plot_decision_regions(X_std,y,classifier=stdada)
效果变好了一些(但实际上初值问题仍然存在)
大规模机器学习与随机梯度下降法 现在我们考虑一个非常巨大的数据集(可能有上百万的数据)
为了更好的进行梯度下降法,我们需要对数据进行一个更好的随机化处理